


Next: Theory Evaluation
Up: Model
Previous: Analogy Representations.
A general hypothesis of this work is that visual information will
prove to be useful in resolving symbolic mismatches. In this section I
will specify this hypothesis: Visual information will help resolve two
different kinds of symbolic mismatches in analogical problem
solving. First, it can help with the generation of mappings. Take, for
instance, where the agent needs to find an alignment between the army
and the ray of radiation. For the sake of simplicity, let's say the
army is represented with the token army and the radiation is
represented with the token ray. The tokens are not identical,
and the system cannot align them. The situation is depicted in Figure
6.
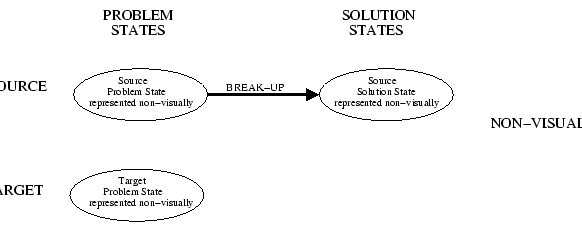
Figure 6:
The ovals along the top represent the solved problem in
memory. For the sake of simplicity, imagine that the solution to the
problem involves only a single transformation. The top left oval
represents the start nv-state. The action break-up, splits
the army up into smaller groups, resulting in many smaller
armies. Every oval in this figure represents a non-visually
represented s-image. The problem state on the bottom is the
tumor problem.
 |
Now imagine the agent has knowledge that both the ray and the army
share the visual abstraction line, because a ray is shaped like
a line, and the army's motion can be abstracted into a line-shaped
path. The agent generates a visual representation of both systems and
finds that there are lines in each, and makes the alignment as a
result of this found similarity. This alignment is brought back to the
non-visual representation and the analogical problem solving process
continues in the non-visual representation.
The second use I predict is in the visual abstraction of
actions. Let's say that to solve the problem the agent needs to break
up the army into smaller armies, and the action it uses to do this is
break-up, which takes a set of things as an argument and outputs
smaller groups. Further, suppose break-up works by finding the
constituent parts of the idea, and dividing them into n
groups. If the ray of radiation is represented such that it does not
have constituent parts, then the action break-up will not work
on it. You can see the state of the agent's knowledge at this point in
Figure 7.
Figure 7:
The bottom two ovals are the problem states of the target and
source in terms of their visual information. As a result of their
visual similarity, an alignment, or mapping, can be found. This allows
the agent to hypothesize the analogous alignment in the non-visual
representation. From here, the agent can attempt the transfer process
in the non-visual representation. It will fail because the action break-up cannot be applied to the ray of radiation.
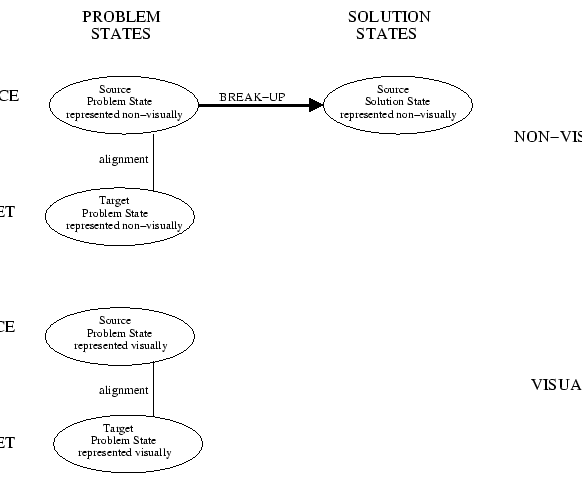 |
Figure 8:
To resolve this transfer of strategy problem, the agent
continues fleshing out the visual representation, visually
instantiating the break-up action into the visual decompose transformation. Since the ray and the soldier path are
abstracted as lines, the decompose function can be transferred from
the source to the target in the visual. The visual solution state can
be generated. But solving the problem in a visual abstraction does not
mean solving it in the more realistic non-visual representation. But
if decompose specifies to break-up, then the visual
representation does no good, because we could have just substituted
break-up in the non-visual to begin with.
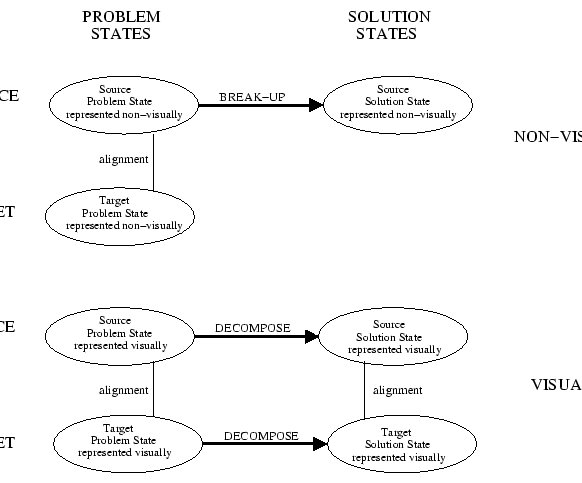 |
Figure 9:
The decompose function specifies to more than one
non-visual transformation. The agent chooses the correct specification
based on the kind of object it is modifying. In this case, it's energy,
so it chooses the more appropriate distribute transformation. It
decomposes the ray correctly. The target solution state represented
non-visually is generated and evaluated. The problem is solved.
 |
The agent can visually instantiate the transformation into one that
can be applied to lines. Let's suppose it visually instantiates into
the visual decompose transformation, which will turn a line into
several thinner lines. This visual transformation can be applied to
both source and target s-images.
Next comes specification, which is translating the
transformation back into an action in the non-visual representation,
which I assume is a more realistic representation. That is, if you
can't translate it back from the visual abstraction, then you won't
really know what to do to the radiation, just a line representing
it.![[*]](file:/usr/local/latex2html/icons/footnote.gif)
But if you can trivially translate back and forth, then there is no
need for the visual abstraction. What makes the visual transformation
useful is that it does not specify back into break-up. The
decompose transformation specifies into break-up when
dealing with, perhaps, entities with constituent parts, but when
dealing with something like energy, whose intensity might be
represented by a number, it specifies into a different
action. Let's call this new transformation distribute, which divides an intensity level by some number
m and allocates the intensity to several sources of energy. This
final nv-state is depicted in Figure 9.
In summary, according to my theory the visual abstractions can provide
an intermediate representation through which otherwise dissimilar
entities and manipulations can be aligned.
See Figure 10 for a diagram of the problem solving
in the general case, when everything can be substituted directly. If
there is a failure in this direct substitution, due to a symbolic
mismatch, then the agent can use visual instantiation to generate
visual representations to attempt to resolve the mismatch. The top
ovals represent the source analog problem, where the top left oval is
the initial state and the top right oval is the solution state. The
bottom left oval represents the input target problem state. From the
mapping stage, there is an analogical mapping between the source
s-image 1 and the target knowledge state 1.
The same transformation that brings the source s-image 1 to the source
s-image 2 is applied to the target s-image 1, leading to the
generation of the target s-image 2, shown as the oval at the bottom
middle. Then the next transformation is transfered, until all the
transformations from the source have been applied to the target,
resulting in the solution state of the target problem.
Figure 10:
This Figure shows the structure of the procedure transfer in
the general case. The things outside the shaded box are given to the
agent: a
complete source problem an incomplete target problem.
The system completes the analogical transfer and stores
the
new s-image sequence for the target problem.
 |
Figure 11:
Flow diagram demonstrating control in theory.
 |
Here is the main algorithm. It takes as input at least the following
items: A memory of potential source series, success conditions, and a
series consisting only of a single problem nv-state (the target
problem). Words in bold represent functions that will be described in
more detail later.
- Evaluate. Run evaluate, where the
knowledge-state argument of evaluate is the last nv-state
currently in the target problem, and the input success
conditions are the specification conditions. If the goal
conditions are met, exit, and the problem is solved. If not, set
the target nv-state to current-target-knowledge-state, then go
on.
- Choose problem solving strategy. Choose a problem
solving strategy from those that have not failed for this target
problem. If all have failed, exit and fail. If analogy is chosen
then go on.
- Retrieve. This is the first step of non-visual
analogical problem solving. Run retrieve, where the single
argument is the input target nv-state. If retrieve fails, mark
analogy as having failed for this problem and return to 2 and
choose another strategy.
- Find mapping. Run find-mapping with the
following arguments: the current-target-knowledge-state and
current-source-knowledge-state. There may be an input suggestion
from a visual mapping that was found. If find-mapping fails to
find a mapping, and visual knowledge state abstraction has not
failed, go on. If it succeeds, Go to 8 to try to transfer the
actions. If it fails because there are no more
states to evaluate, or because visual knowledge state abstraction
has failed, go to step 3 and try another retrieval.
- Generate new s-images. This is the first step of knowledge state visual instantiation. There are multiple ways to
visualize something. Each time this step is reached, search
through the space of visual instantiations for the source and
target, creating new visual instantiations by running: generate-s-image where its argument is the
current-target-knowledge-state. It will generate the
current-target-s-image. Then run generate-s-image where its
argument is the current-source-knowledge-state. It will generate
the current-source-s-image. If there are no more new visual
instantiations to be made, mark knowledge state visual
instantiation as having failed for this mapping and go to 4.
- Find visual mapping. Map the s-images by running find-mapping with the following arguments: The
current-target-s-image and the current-source-s-image. If you
fail, go to 5 and try to get a different visual instantiation to
try. If you succeed, go on.
- Transfer mapping. Run transfer-mapping with the
following arguments: the new visual mapping and its s-images, and
their corresponding nv-states. It will generate a suggested
mapping for the nv-states. Use this suggestion, going back to 4,
the mapping stage. This is the last step in knowledge state visual
instantiation.
- Transfer actions. Run transfer-manipulation,
attempting to transfer the current source nv-state's action to the
target. Go on to try to apply it.
- Apply action. Run the associated action on the current
target knowledge state. If it works, generating a new nv-state, go
to 1 and evaluate. If it does not work, go on to try manipulation
visual instantiation at 10. If visual instantiation has been
marked as failed for this mapping, go back and try another mapping
at 4.
- Generate s-images. Generate new s-images as in step 5,
if 1) there are no s-images for the current nv-states, or 2) the
current s-images have been marked as having failed.
- Generate transformation. Run generate-transformation and find the visual analog of the action
of the current source nv-state. If this function fails, mark
visual manipulation abstraction as having failed for this source
and target nv-state series and go back to apply action at 9.
- Apply-manipulation. Apply this transformation to the
corresponding element in the current source visual s-image. This
makes a new s-image.
- Transfer manipulations. Run transfer-manipulation, attempting to transfer the current source
s-image's transformation to the target. If the transformation
cannot be applied, go back to 5, marking this visual instantiation
as failed. Else go on.
- Apply transformation. Apply this transformation to the
current target s-image. This makes a new s-image. Run apply-manipulation to do this.
- Generate action. Run generate-action to specify
the abstract transformation into an action that can be taken on the
current target nv-state. If no unused specifications remain, mark
visual manipulation abstraction as having failed for this source
and target s-images. Go back to 10 and generate new s-images. If an
action is generated, associate that action with the nv-state and go
to 9 to apply it.
Now I will describe the functions referred to above in more detail.
- Name: Evaluate
- Input: Success Conditions, nv-state (nv-state)
- Output: [success | failure]
- Process:
- Evaluate will run a simple simulation of the system as
it stands in the input nv-state. The details of how this will
work will be written up in the dissertation, but are not a part of my
theoretical claims.
- Name: Retrieve
- Input: knowledge state (knowledge state)
- Output: knowledge state-series (knowledge state-series)
- Process:
- If the input knowledge state is an s-image, then this function
will return series represented in Covlan. If the input
knowledge state is a nv-state, it will return nv-state series.
- The function will reject any series that has been
marked as failed for the input knowledge state's series.
- If there is a conflict, the best matching series is
returned. The details of how retrieval happens will be
fleshed out over the course of the dissertation and is not
important to my theoretical claims.
- If all potential analogs have been marked as failed,
mark analogical problem solving has having failed for this
source nv-state series and exit.
- If it succeeds, set the retrieval problem state to
current-source-knowledge-state.
- Name: find-mapping
- Input: knowledge state1 (knowledge state), knowledge state2 (knowledge state)
- Output: a mapping
- Process:
- The details of the mapping process will be determined
in the process of the dissertation and are not important to
my theory.
- Name: generate-s-image
- Input: knowledge-state (nv-state)
- Output: an s-image, visual instantiation connections between
the nv-state and the s-image
- Process:
- The agent has knowledge of what each object looks
like. This means that each object is associated with an
element or complex of elements and relations. Default values
(such as where something will be placed in an s-image) will be
determined by the relations of objects with other objects in
the nv-state. There is psychological data (Richardson et
al., 2001) showing how actions are associated with image
placement I will use to constrain how this works. This module
needs considerable fleshing out.
- Name: transfer-mapping
- Input: mapping (mapping), knowledge state1 (knowledge state),
knowledge state2 (knowledge state)
- Output: mapping or failure
- Process:
- Generate a new symbol for the mapping.
- Associate with the new mapping new versions of all the maps.
- Change the referents of all the maps to what is
connected to them with the visual instantiation connections.
- Name: transfer-manipulation
- Input: knowledge state1 (knowledge state),
manipulation (manipulation),
knowledge state2 (knowledge state)
- Output:
- Process:
- Take the manipulation connected to knowledge state1 and
connect it to knowledge state 2. Specifically, connect the
manipulation to the analogous entity or entities in knowledge state2.
- Transfer all manipulation arguments to the new
manipulation. If an argument has an analog in snapshot2, use
that. If it it does not, transfer it literally.
- Name: apply-manipulation
- Input: knowledge state1 (knowledge state),
manipulation (manipulation)
- Output: another link in knowledge state1's series
- Process:
- Generate a new knowledge state, connected in series to
knowledge state1. This new knowledge state is like knowledge state1 except it has
the manipulation applied to it. If this cannot be done, exit
and fail. Else exit with success.
- Name: generate-action
- Input: transformation1 (transformation),
knowledge-state1 (knowledge-state)
- Output: an action associated with knowledge-state1
- Process:
- Retrieve an unused candidate action from the specifications of
transformation1. Take into account the transformation, and
what it will be applied to in knowledge-state1.
- Name: generate-transformation
- Input: knowledge-state1 (knowledge-state),
action1 (action)
- Output: transformation, and possibly s-images.
- Process:
- If there is no s-image associated with
knowledge-state1, make one.
- If there is no s-image associated with
knowledge-state1's target knowledge-state, make one.
- Abstract action1 into a visual transformation
appropriate to the visual abstraction in the s-image.
Next: Theory Evaluation
Up: Model
Previous: Analogy Representations.
Jim Davies
2002-09-12